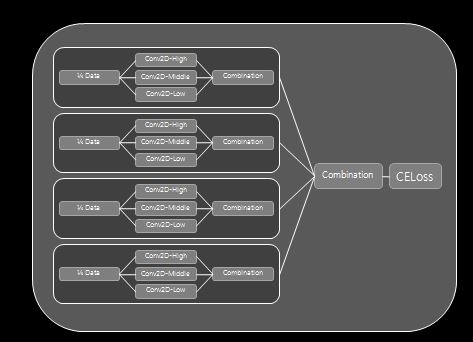
Classification model by English phonetic nationality
Deep learning / Voice processing / Code review
해당 사이트의 글 그림, 디자인의 저작권은 AlcoholWolf에게 있습니다
text pictures and designs on the site are copyrighted by Alcohol Wolf
무단 도용, 퍼가기는 처벌의 대상이 될 수 있습니다
Unauthorized theft or scooping may be subject to punishment